RDBMS:关系型数据库(Relational database management system)
SQLite
一个独立的、基于文件的、完全开源的 RDBMS
优点:
- 轻量便携,占用空间小(600K),不需要额外的依赖
- 无服务(不需要重启或停止),数据库存储在单个文件中
- 适合嵌入式 APP 或开发的快速测试,数据迁移方便
缺点:
- 并发能力有限,单个时间戳只有一个进程能修改数据库
- 不支持用户权限,权限控制依赖底层系统的文件访问权限
- 不适用于大数据量(1TB)/高写入量的场景,不支持网络访问
分类目录归档:学习
RDBMS:关系型数据库(Relational database management system)
一个独立的、基于文件的、完全开源的 RDBMS
优点:
缺点:
体重指数 BMI = 体重/身高的平方(国际单位 $kg/m^2$)
BMI 只能反映全身性肥胖,无法衡量内脏脂肪
单纯使用 BMI 来判断肥胖与否,是存在很大偏差的。对经常运动健身的人群来说,他们通常肌肉含量较高,而肌肉比脂肪的质量大,往往会导致其 BMI 也是
适用内置库实现 json 的基本操作
import json
food_ratings = {"organic dog food": 2, "human food": 10}
json.dumps(food_ratings) # 将 Python 字典转换为 JSON 对象
# '{"organic dog food": 2, "human fooMean Shift 算法,又称为均值漂移算法
核心思想:
算法流程:
$$ S_h\left(x\right)=\left(y\mid\left(y-x\right)\left(y-x\right)^T\leqslant h^2\right) $$ 2. 计算该
样条(spline)通常是指分段定义的多项式参数曲线
样条函数是一种由分段多项式拼接而成的平滑函数,可用于逼近或插值数据
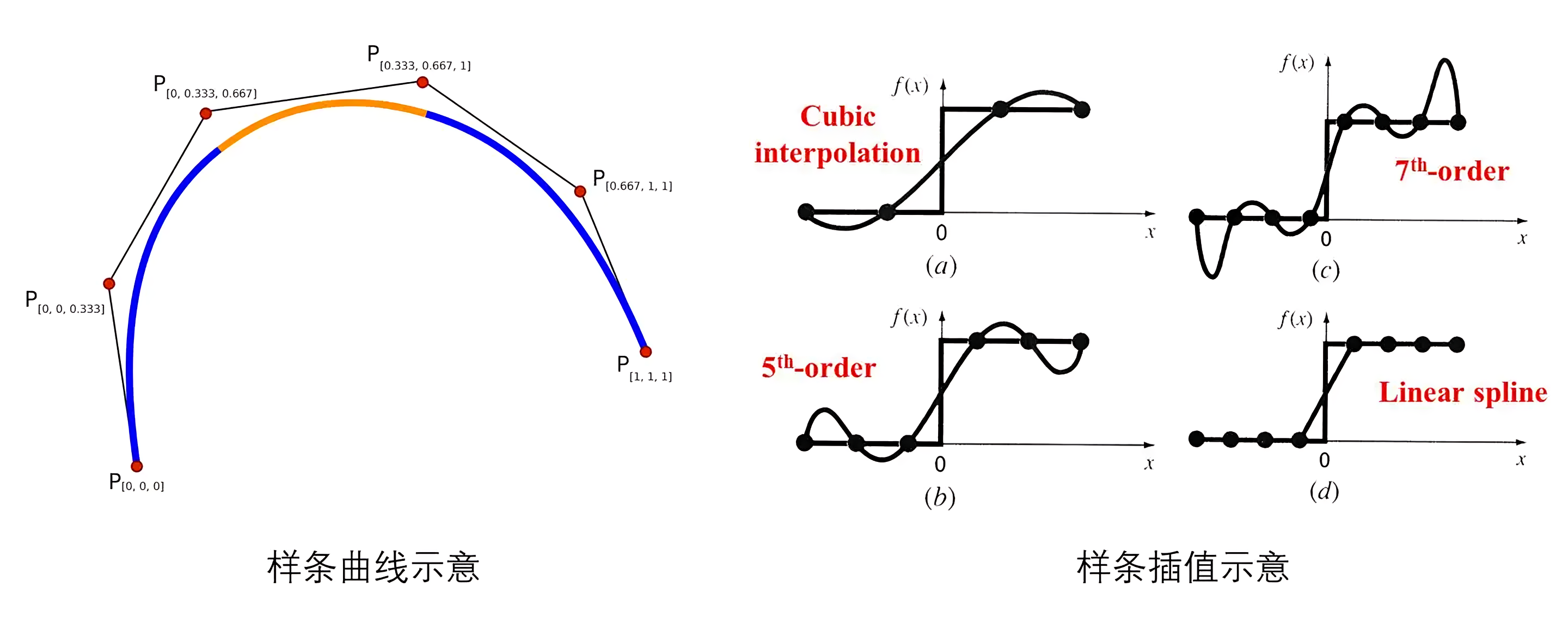
常见的样条函数:
| 线性样条 | 二次样条 | 三次样条 | B样条(B-spline) |
|---|---|---|---|
| 每个子区间上使用一阶多项式,即直线段<br><br>它们在节点处具有零阶连续性,即函数值连续,但导数不连续 | 在每个子区间上使用二阶多项式<br><br>在节点处通常要求函数值和一阶导数连续 | 在每个子区间上使用三阶多项式<br><br>在节点处要求函数值、一阶导数和二阶导数都连续 |
MD5:32 位,单向哈希,不可逆,速度快,破解难度低
SHA256:256 位,单向哈希,不可逆,速度较快,破解难度中等
BCrypt:可变位数,单向哈希,不可逆,速度慢,破解难度高
PBKDF2:可变位数,单向哈希,不可逆,速度可调,破解难度可调
Scrypt:可变位数,单向哈希,不可逆,速度慢,破解难度高
加盐,在输入信息中随机添加字符串(salt)以提高哈希算法的安全性
MD5 消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以
摘自 Joy Triggers: How to Find Happiness on Demand
分库:将表按照某种规则拆分到多个数据库中,来保证系统的稳定和性能
分表:将表中数据按照某种规则拆分到多张表中,提升查询效率
分库分表的原因
单表超 500 万行,或容量超 2GB 时推荐分库分表——阿里开发手册
分库分表的常见方法
将某个库中的表拆分到多个库,一般按照业务维度拆分
优点:降低单数据库服务的压力,增加系统可用性;业务清晰,
用美国股票总市值与 GDP 的比值来衡量股票市场的估值
巴菲特认为,当该指标介于0.9和1之间,则市场被视为估值合理,而当该比率超过1.2则认为估值过高,在该指标接近2时买入美股,相当于“玩火”
20240710:“巴菲特指标”升至 1.96,达到 2021 年底以来的最高水平
估值 =(3 年平均增速 x 100+10)x 确