发表评论
159 views
分类目录归档:algorithm
生存分析(Survival analysis),也称失效分析
起始事件和失效事件是相对应,并且可应用于不
倒数排名融合(Reciprocal Rank Fusion,RRF)
RRF 的核心公式: $$ RRFscore(d\in D) = \Sigma_{r\in R}\frac{1}{k+r(d)} $$
RRF 的简单示例:
docA 在三次不同的检索策略中出现,检索排名分别 1、2、1docA 的最终 RRF 得列线图(Alignment Diagram),又称诺莫图(Nomogram 图)
示例说明(以泰坦尼克邮轮数据集中,乘客的死亡二分类预测为例):
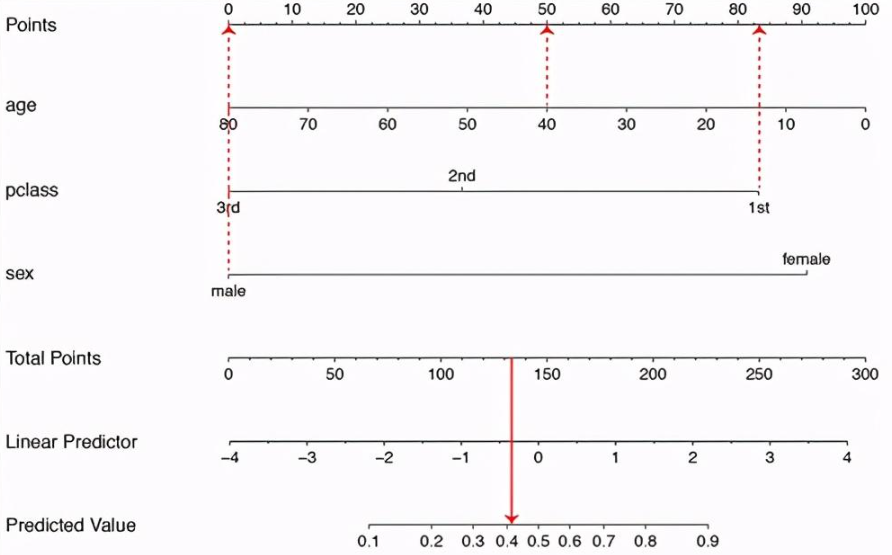
Points 是每一个特征的评分参照,Total Points 是所有特征的汇总评分参照Linear Predictor 是汇总评分的线性映TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution) ,也称优劣解距离法,是一种常用的组内综合评价方法,能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距
针对多标准/多目标决策问题(MCDM/MCDA),决策者需要面对多种决策标准和可行决策方案,TOPSIS 的作用就是帮助决策者综合考虑多个决策标准,在多个可行决策方案之间找到最优解
TOPSIS 示例:评估 5 所研究生院的教育质量
5 所研究生院的评估数据及其权重如下:
| 院校 | 人均专著 $x_1$ (本/人) |
|---|
UMAP 算法
UMAP 定义的概念解释与补充:
t-SNE 算法
算法过程概述:
调查问卷分析的一般流程:
LSH(locality sensitivity Hashing,局部敏感性哈希)算法
以相似文档检索为例,说明 LSH 的算法过程
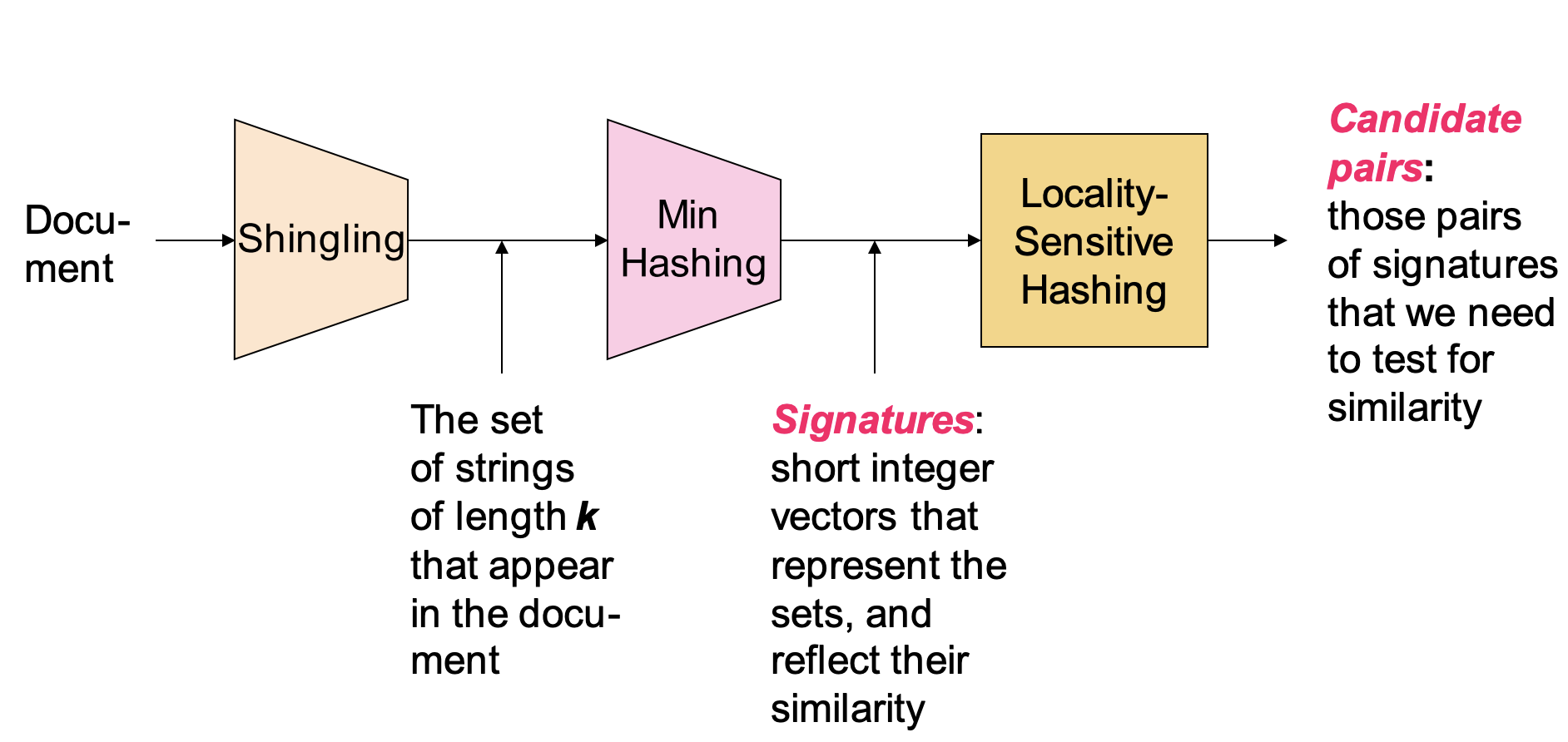
Shingling,文档进行向量化表示
Min-Hashing,对文档信息进行降维