Agent Harness 描述了用于管控 LLM 的完整软件基础设施
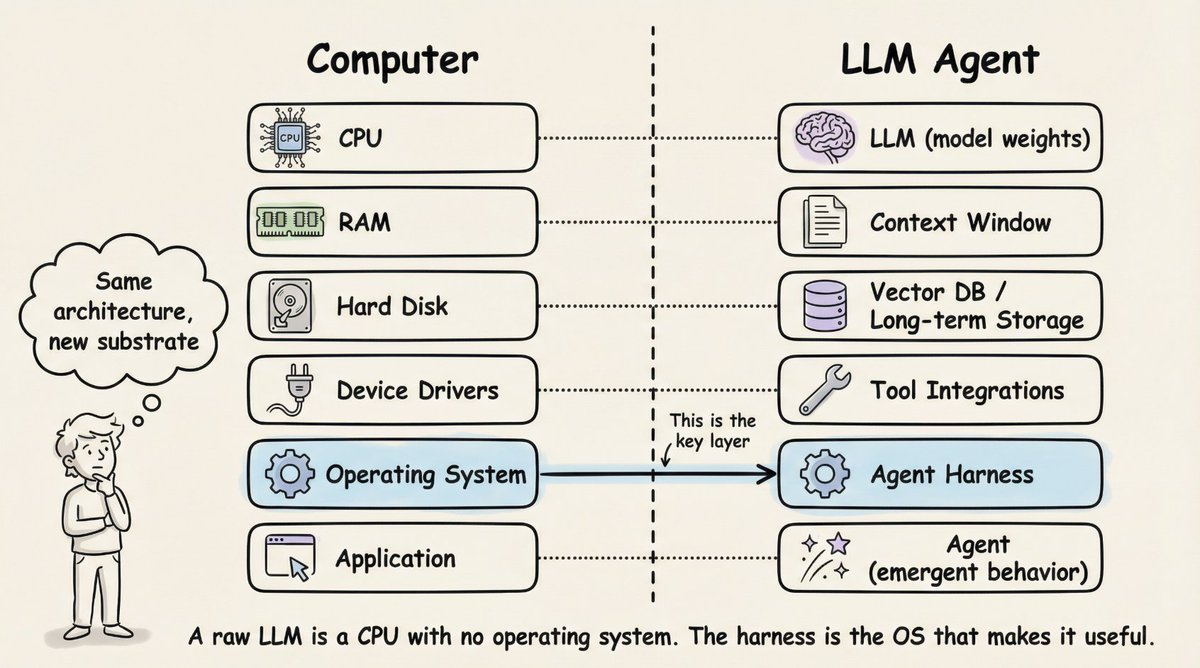 图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge
图源 - 《Scaffolded LLMs as Natural Language Computers》 by Beren Millidge
Harness 的 12 个核心组件
- 编排层(Orchestration Loop):实现思考-行动-观察(TAO)循环,作为心脏维护最低限度的编排工作(dumb loop,笨循环),避免影响模型的决策推理
- 工具层(Tools):管理工具的注册、验证、沙盒执行与结果格式化;常用的六类工具:文件操作、搜索、执行、网络访问、代码辅助和子智能体管理;常见的工具类型:函数/托管服务/