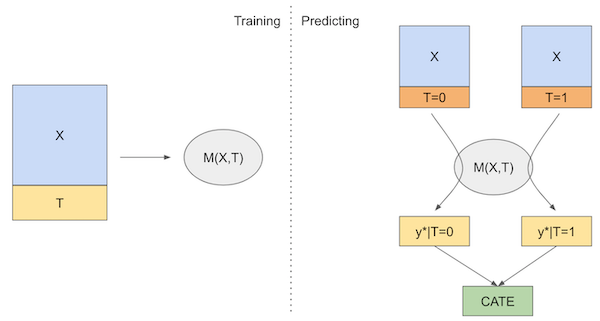
前置知识:双重差分法 DID、合成控制法、双向固定效应 TWFE
前置算法回顾
已知双重差分法 DID 的线性模型可表示如下: $$ Y_{it} = \beta_0 + \beta_1 Post_t + \beta_2 Treated_i + \beta_3 Treated_i Post_t + e_{it} $$
- 其中
post表示时间虚拟变量,treated表示干预虚拟变量
而通过引入个体/时间的固定效应,可以将 DID 表示为 TWFE 的形式: $$ \hat{\tau}^{did} = \underset{\mu, \alpha, \