中文标题:SMedBERT_医学语义知识增强型预训练模型
英文标题:SMedBERT: A Knowledge-Enhanced Pre-trained Language Model with Structured Semantics for Medical
发布平台:ACL
发布日期:2021-01-01
引用量(非实时):22
DOI:10.18653/v1/2021.acl-long.457
作者:Taolin Zhang, Zerui Cai, Chengyu Wang, Minghui Qiu, Bite Yang, Xiaofeng He
文章类型:conferencePaper
品读时间:2022-09-02 11:12
1 文章萃取
1.1 核心观点
本文首次提出并开源了基于医学类大规模语料并完成医学知识注入的自然语言处理预训练模型SmedBERT。SmedBERT模型先借助PEPR排序算法筛选出每个实体在知识图中的邻接实体,之后构建混合注意力机制,借助门控机制选择性地融合邻接实体及其类型信息,最后通过两个自监督的预训练任务(遮掩实体预测MMeM,遮掩邻接实体预测MNeM)引导知识的注入理解过程。最终训练得到的SmedBERT模型性能十分优秀。
1.2 综合评价
- 在融合结构化知识方面借助并融合了很多传统的技巧(PageRank,sampled-softmax,负采样 ,门控机制),也有很多独特创新(PRPR,混合注意力等)
- 实验分析严谨,最终表现显著优于其他常见模型,对代码和模型进行了开源
- 符号定义很多,格式也有些随意,阅读体验不太好。比如得分矩阵$V$的下标既表示实体,也可能表示迭代次数(注意:本笔记中的部分符号与论文存在部分差异)。
1.3 主观评分:⭐⭐⭐⭐
2 精读笔记
2.1 背景知识
传统大规模预训练模型(简称PLM,如BERT、RoBERTa)专注于对文本内容的嵌入表示,对应的常见三种改进方向包括:Transformer编码器结构、自监督任务和多任务学习
知识增强型预训练模型(KEPLM)主要有以下三种分类:
- 基于实体嵌入的知识增强:如ERNIE-THU、KnowBERT
- 基于实体描述的知识增强:如E-BERT、KEPLER
- 三元组转语句的知识增强:如KBERT、CoLAKE
医药领域的PLM的常见三种分类:
- 通用PLM基于医药领域语料的继续训练:如BioBERT、BlueBERT、SCIBERT
- 基于大规模医院领域语料的从零开始训练:如PubMed,未收录词(OOV)问题
- 使用其他自监督任务进行预训练:如MC-BERT通过遮盖医疗类实体和短语来学习其中复杂的结构和概念;DiseaseBERT借用医学术语及其类别标签进行预训练
传统知识增强预训练模型(KEPLM)多关注于知识图中的三元关系(头实体-实体关系-尾实体),而忽视实体间的邻接结构所包含的语义信息。而本文则从以下两个方面补充了邻接实体的相关信息:
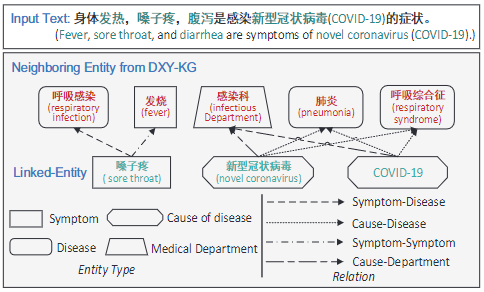
- 不同实体可能具备相似的邻接实体,这能提供额外的语义信息。比如”肺炎“或”呼吸综合征“都可能是由”新型冠状病毒“引起的(原因-病症类关系)
- 每个实体的所有邻接实体可以汇总构成该实体的”上下文“,以补充知识结构类信息
知识图与邻接实体-图示:
2.2 模型细节
模型的输入词元:${w_1,w_2,...,w_n}$
模型的隐藏层输出(词元的嵌入表示):${h_1,...,h_n}$,维度为$d_1$
语料长度为$M$,其中被提及的实体词(mention-span)$e_m$构成的集合为$E$
知识图谱:$G=(\varepsilon,R)$,其中$\varepsilon$和$R$分别表示实体和实体间的关系
知识三元组:$(e_h,r,e_t)$,其中符号分别表示头实体、实体关系、尾实体
本文使用$TransR$模型生成实体和关系的嵌入表示:$\Gamma_{ent}$,$\Gamma_{rel}$,维度为$d_2$
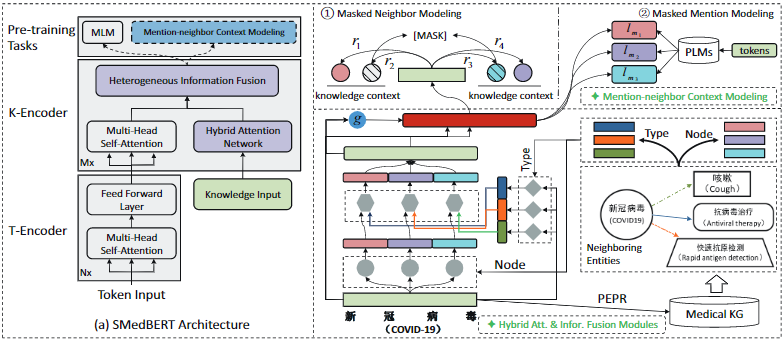
本文提出的SMedBERT主要包括三个部分:
- TopK实体排序模块:针对每个被提及实体词(mention-span)找到$K$个最重要的邻接实体
- 邻接实体混合注意力:将结构化语义知识(主要包括类别信息、邻接节点信息和门控类信息)进行融合,并注入编码器层
- 邻接实体上下文建模:以遮掩实体或邻接实体为建模目标,促进模型对不同实体的理解,也提升改善实体和邻接实体之间的交互作用
SMedBERT的模型结构(左)和模型细节(右):
2.2.1 TopK实体排序模块
TopK实体排序模块-PEPR(Personalized PageRank):
- PEPR 改编自谷歌的 PageRank 排序算法,能迭代式地计算出邻接节点的权重并进行排序
- 初始化节点$e_m$的得分向量$V=[v_{e_1},...,v_{e_M}]$,其中$M$为实体的总数量。当$e_i \in E$时,$v_{e_i}=\frac{t_{e_i}}{T}$,其中$t_{e_i}$表示$e_i$在语料中的词频;当$e_i \notin E$时,$v_{e_i}=\frac{1}{M}$
- 得分向量的第$l$次迭代过程:$V^l=(1-\alpha)A\cdot V^{l-1}+\alpha P$,其中$A$表示标准化的邻接矩阵,$\alpha$表示阻尼因子(随机跳转的概率),$P$表示服从均匀分布的跳转概率矩阵
- 重复$n$次以上迭代过程,得到节点$e$的权重向量$V^n$,选择其中最重要的$K$个实体,组成重要邻接实体的集合$N_{e_m}={e_m^1,e_m^2,...,e_m^K}$
2.2.2 邻接实体混合注意力
知识点补充说明:自注意力池化
- 自注意力池化机制最初是用于将词向量联合转化为句向量的方法
- 将词元的嵌入表示按顺序进行拼接,得到句子的矩阵形式表示$H=[h_1,..,h_n]$
- 通过以下变化计算句子中每个词元的权重:$A=softmax(W_2tanh(W_1H^T))$
- 最终的句子嵌入表示为词元的加权求和$M=AH$,更多细节可参阅论文原文
- 自注意力池化可看作使用self-attention的方法来替换原本的最大池化操作
邻接实体混合注意力(Mention-neighbor Hybrid Attention)需要分别提取邻接实体的类别信息、实体的邻接节点信息,并借助门控单元控制知识(邻接信息)的注入
- 计算邻接实体的类别注意力(Neighboring Entity Type Attention)
- 筛选实体$e_m$的$K$个重要邻接实体中所有类型为$\tau$的邻接实体,并构成集合$E_{e_m}^{\tau}$
- 实体$e_m$关于$\tau$的类型信息可近似看作所有类型为$\tau$的邻接实体的嵌入表示之和,即:$$h_{e_m}^{\tau}=\Sigma_{e^i_m\in E_{e_m}^{\tau}}h_{e_m^i}$$
- 假设实体$e_m$对应的多词元嵌入表示为$(h_i,...,h_j)$,其中$h_i \in R^{d_1}$,通过以下公式可将多词元的嵌入表示转化为实体的嵌入表示$h'_{e_m}\in R^{d_2}$:
$$h'_{e_m}=LN(\sigma(f_{sp}(h_i,...,h_j)W_{be}))$$
- 上式中,$LN$表示层归一化,$\sigma$表示激活函数(本文中在此使用GELU作为激活函数),$f_{sp}$表示自注意力池化算子,$W_{be}\in R^{d_1\times d_2}$为可训练参数
- 根据实体的嵌入表示和实体关于$\tau$的类型信息,计算实体关于类别$\tau$的注意力得分:
$$\alpha'_{\tau}=tanh(h'_{e_m}W_t+h^{\tau}_{e_m}W_{t'})W_{\alpha}$$
- 上式是一种加性注意力得分的计算,以实体信息$h'{e_m}q$作为查询$q$,实体关于$\tau$的类型信息$h^{\tau}{e_m}$作为键$k$,得出实体对于类别为$\tau$的注意力得分。
- 上式中,$W_t\in R^{d_2\times d_2}$,$W_{t'}\in R^{d_2\times d_2}$,$W_{\alpha}\in R^{d_2\times 1}$均为可训练参数
- 同理,实体$e_m$针对不同的$\tau$都会有一个注意力得分$\alpha'$,将所有针对类型的注意力的得分汇总并进行归一化(注意力得分转为注意力权重,权重和为1),使得$\alpha'$转化为$\alpha$
实际情况中,词级词元可能很难组成实体。因此本文中主要使用字符级词元
- 实体的邻接实体注意力(Neighboring Entity Node Attention)
- 假设实体$e_m$存在一个类型为$\tau$的邻接实体$e_m^i$,其对应的嵌入表示为$h'_{e_m^i}$
- 则实体$e_m$关于邻接实体$e_m^i$的注意力得分如下:
$$\beta'_{e_me^i_m}=\frac{(h'_{e_m}W_q)(h_{e^i_m}W_k)^T}{\sqrt{d_2}}\alpha_{\tau}$$
- 上式中,$W_q\in R^{d_2\times d_2}$,$W_k\in R^{d_2\times d_2}$均为可训练参数,$d_2$是实体嵌入表示的维度
- 同理,实体$e_m$针对每个邻接实体都有一个注意力得分,通过归一化转化为权重:
$$\beta_{e_me^i_m}=\frac{exp(\beta'_{e_me^i_m})}{\Sigma_{e^i_m\in N_{e_m}}exp(\beta'_{e_me^i_m})}$$
- 加权汇总实体$e_m$的所有邻接实体的混合信息:
$$\hat{h}'_{e_m}=\Sigma_{e^i_m\in N_{e_m}}\beta_{e_me^i_m}(h_{e^i_m}W_v+b_v)$$
- 借助MLP和残差连接进一步丰富实体$e_m$的邻接实体混合信息:
$$\overline{h}'_{e_m}=LN(\hat{h}'_{e_m}+(\sigma(\hat{h}'_{e_m}W_{l1}+b_{l1})W_{l2}))$$
- 其中,$W_v\in R^{d_2\times d_2}$,$W_{l1}\in R^{d_2\times 4d_2}$,$W_{l2}\in R^{4d_2\times d_2}$均为可训练的网络参数,$b_v\in R^{d_2}$,$b_{l1}\in R^{4d_2}$均为可训练的偏置项
- 基于门控机制的知识注入
- 拼接融合实体$e_m$的信息和邻接实体的混合信息
$$\begin{align} h'_{e_{mf}}&=\sigma([\overline{h}'_{e_{mf}}||h'_{e_m}]W_{mf}+b_{mf}) \\ \widetilde{h}'_{e_{mf}} &=LN(h'_{e{mf}}W_{bp}+b_{bp}) \end{align}$$
- 上式中,$W_{mf}\in R^{2d_2\times 2d_2}$,$W_{bp}\in R^{2d_2\times d_1}$均为可训练的网络参数,$b_{mf}\in R^{2d_2}$,$b_{bp}\in R^{d_1}$均为可训练的偏置项。$||$表示拼接操作。结果输出$\widetilde{h}'{e{mf}} \in R^{d_1}$。
- 本文研究发现,以词元$h_i$为基本单位进行知识的注入的效果更好。同时本文将门控单元的输出$g_i$作为控制知识是否注入的开关,并输出完成知识注入的词元嵌入表示:
$$\begin{align} g_i&=tanh(([h_i||\widetilde{h}'_{e_{mf}}])W_{ug}+b_{ug}) \\ h_{if} &=\sigma(([h_i||g_i*\widetilde{h}'_{e_{mf}}]W_{ex}+b_{ex})+h_i \end{align}$$
- 上式中,$W_{ug}\in R^{2d_2\times d_1}$,$W_{ex}\in R^{2d_2\times d_1}$均为可训练的网络参数,$b_{ug}\in R^{d_1}$,$b_{ex}\in R^{d_1}$均为可训练的偏置项。$*$表示点积操作(逐元素相乘,element-wise multiplication)
2.2.3 邻接实体上下文建模
构建两个新的预训练任务(MNeM,MMeM),充分利用注入的结构化知识
- 借助上一节最终的知识注入版词元嵌入表示,构建实体的知识注入版嵌入表示:
$$h_{mf}=LN(\sigma(f_{sp}(h_{if},...,h_{jf})W_{sa}))$$
- 本文借鉴了skip-gram模型中随机负采样以及TransR模型中的得分函数,最终遮掩邻接实体建模(Masked Neighbor Modelng,MNeM)任务对应的损失函数:
$$L_{MNeM}=\Sigma_{N_{e_m}}log\frac{exp(f_s(\theta))}{exp(f_s(\theta))+K\cdot E_{e_n\sim Q(e_n)}[exp(f_s(\theta'))]}$$
- 上式中,$\theta$表示知识三元组$(e_m,r,e^i_m)$,其中$e^i_m \in N_{e_m}$是$e_m$的邻接实体。$\theta'$是负采样得到的错误知识三元组,负采样过程满足$Q$分布 ,其中的采样结果为错误的邻接实体$e_n$,$K$表示采样个数。$f_s$为相容性函数(compatibility function),其定义如下:
$$f_s(e_m,r,e^i_m)=\frac{h_{mf}M_r+h_r}{||h_{mf}M_r+h_r||}\cdot \frac{(h_{e^i_m}M_r)^T}{||h_{e^i_m}M_r||}\mu$$
上式借鉴自TransR模型中的得分函数,描述了”头实体+实体关系“与”尾实体“之间的相容性。其中$M_r$为可训练参数,$\mu$表示缩放因子(超参数),$f_s=\mu$时二者相容性最高
针对每一个负采样结果,都需要计算$f_s(\theta')$。为了降低计算成本,可考虑对$f_s$进行化简,去除重复的$h_{e^n}M_r$计算
$$h_{mf}M_r+h_r\cdot (h_{e^i_m}M_r)^T= \left[ \begin{matrix} h_{mf} & 1 \\ \end{matrix} \right] \left[ \begin{matrix} M_r \\ h_r \end{matrix} \right] \left[ \begin{matrix} M_r \\ h_r \end{matrix} \right]^T \left[ \begin{matrix} h_{e_n} & 0 \\ \end{matrix} \right]^T =\left[ \begin{matrix} h_{mf} & 1 \\ \end{matrix} \right] M_{P_r} \left[ \begin{matrix} h_{e_n} & 0 \\ \end{matrix} \right]^T $$
- 最后再补偿负采样函数$Q(e^i_m)$引入的偏移量,最终的$f_s$如下所示:
$$f_s(e_m,r,e^i_m)=\frac{\left[ \begin{matrix} h_{mf} & 1 \\ \end{matrix} \right] M_{P_r}} {||\left[ \begin{matrix} h_{mf} & 1 \\ \end{matrix} \right] M_{P_r}||} \cdot \frac{\left[ \begin{matrix} h_{e_n} & 0 \\ \end{matrix} \right]}{||\left[ \begin{matrix} h_{e_n} & 0 \\ \end{matrix} \right]||} \mu-\mu logQ(e^i_m)$$
- 根据BERT模型提取到的词元嵌入表示$h_{ip}$,构建实体的另一种嵌入表示:
$$h^{bert}_m=LN(\sigma(f_{sp}(h_{ip},...,h_{jp})W_{sa}))$$
- 最终遮掩实体建模(Masked Mention Modelng,MMeM)任务对应的损失函数:
$$L_{MMeM}=\Sigma_{m_i}^{M_s}||h_{m_if}-h_{m_i}^{bert}||^2$$
- 上式为常见的均方误差损失,描述了两种方式得到的实体嵌入表示的差异性,其中$M_s$表示所有的样本出现的实体集合
- 最终整合所有的损失函数,得到SmedBERT的目标函数:
$$L=L_{EX}+\lambda_1 L_{MNeM}+\lambda_2 L_{MMeM}$$
- 上式中,$L_{EX}$表示常规BERT的语序预测和词元遮盖预测任务对应的损失;两个$\lambda$为超参数,用于调整不同损失函数的权重
2.3 实验分析
预训练数据:爬取并清洗丁香园论坛的文本数据,593万文本段,30亿词元(4.9GB)
预设参数:$d_1=768,d_2=200,K=10,\mu =10,\lambda_1=2,\lambda_2=4$
知识图谱:OpenKG中与病症相关的中文知识和DXYKG(丁香园自己构建的医疗类图谱),实体数分别约为13.96万和15.25万,知识三元组数分别约为100.78万和376.47万
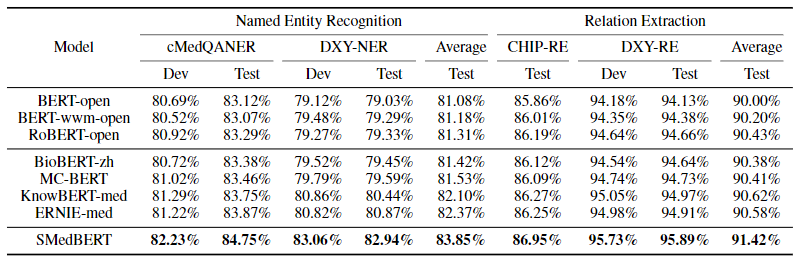
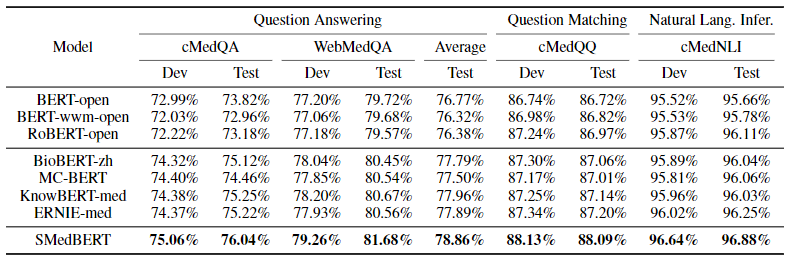
下游任务:使用CBLUE中文医疗NLP基准测试,主要包括命名实体识别(DXY-NER),两个关系抽取(DXY-RE,CHIP-RE),知识问答(WebMedQA)等任务
超参实验:K值选择对模型效果的影响
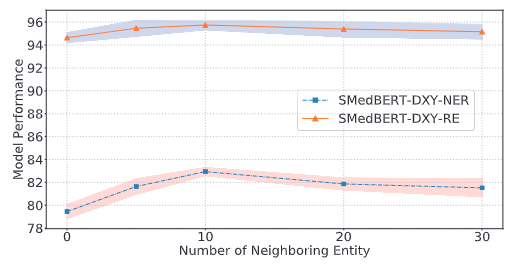
- 随着K值的增加,邻接实体的信息被逐渐注入
- 当K取值过高时,会引入噪声,导致模型效果先增后减
- 当$K=10$时,模型效果大概是最优的
消融实验:
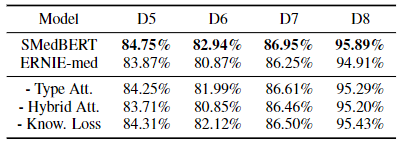
- 混合注意力的引入对性能提升最大
其他实验:
- 针对语义相似度问题对比,SmedBERT在不同类型数据均存在明显的优势
- 针对不同实体覆盖率情况进行对比,SmedBERT优势明显且稳定
相关资源
- 论文在线地址
- 源码+预训练模型
- 本地文件地址:2021_SMedBERT_Zhang et al.pdf
- 本地Zotero地址:2021_SMedBERT_Zhang et al.pdf