前置知识: 10.《动手学深度学习》注意力机制
普通线性注意力
原始 Tansformer(左) VS 线性 Tansformer(右):
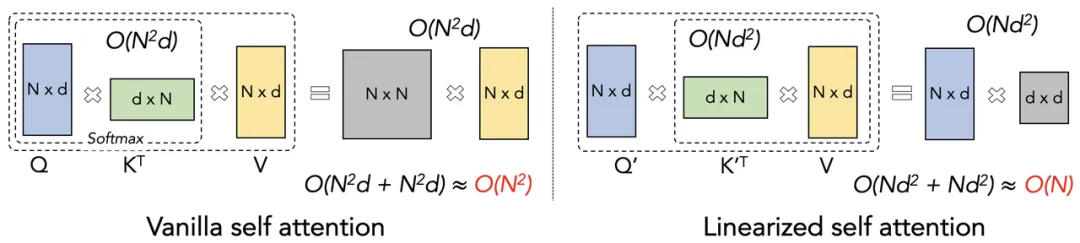
- N:序列长度,在自然语言处理任务中,指句子中 Token 或词的数量。
- d:特征维度,即每个元素(如单词的词向量)的维度。
- O(N²d)、O(Nd²) :计算复杂度。大 O 描述了计算量随输入序列变长的增长速度,如 O(N²d) 表示计算量与 N² 和 d 成正比 。
- Q(Query):“查询” 矩阵,用于在自注意力机制中向其他元素询问相关信息。
- K(Key):“键” 矩阵,与查询向量配合,用于计算相关性。
- V(Value):“值” 矩阵,是 Q 和 K 计算出的注意力权重,对 V 进行加权求和,会得到自注意力机制的最终输出。
- Kᵀ:K 的转置矩阵,在矩阵运算中,为使矩阵维度匹配进行乘法运算,常需对矩阵进行转换操作。
- Q′、K′:在线性化自注意力机制中,对 Q 和 K 进行某种变换后的矩阵
总结:
- 线性注意力机制通过将“先左乘”改为“先右乘”,使得计算复杂度从 $O(N^2)$ 变为 $O(N)$
- 线性注意力机制的关键在于利用“核技巧”来加速注意力矩阵计算,避免 $n×n$ 矩阵乘法
Flash Attention
Flash Attention 框架总览( 论文地址 2022-05)::
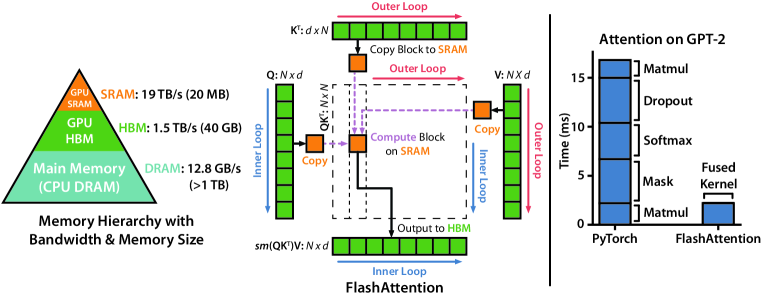
- 左:利用 GPU 硬件特性,避免高带宽内存(HBM)和静态随机存取存储器(SRAM)之间的数据传输
- 中:对输入序列分块,然后进行遍历计算,同时保存中间结果用于最终的 sofxmax 计算
- 右:Flash Attention 使得 GPT2 的运行速度加快 7.6x,同时保持了更低的内存占用 $O(N)$
Flash Attention 的计算加速核心在于避免高带宽内存(HBM)的频繁访问
Flash Attention v2 的改进( 论文地址 2023-07):
- 调整算法,尽量用矩阵乘法来替代非矩阵乘法,发挥 GPU 的矩阵运算优势
- 改善并行化,优化线程块与 CUDA 线程束(Warp)间的工作分配
- 减少通信和共享内存的读写操作,提高长序列的 GPU 利用率
最终的 Flash Attention v2 比第一版快约 2 倍,达到 A100 上理论最大 FLOPs/s 的 50-73%
Flash Attention v3 的改进( 论文地址 2023-07):
- 将数据移动和 Tensor 核的异步执行分割成独立的 Warp,规避内存和指令延迟问题
- 重新设计算法,实现 softmax 计算能够与优化的矩阵乘法(GEMM)操作异步执行
- 利用 FP8 Tensor Cores进行前向传播算法的GEMM计算,并减轻 FP8 可能的精度损失
Flash Attention v3 达到 A100 上理论最大 FLOPs/s 的 75%,目前在官网处于测试阶段
Lightning Attention
Lightning Attention-2 的结构框架:
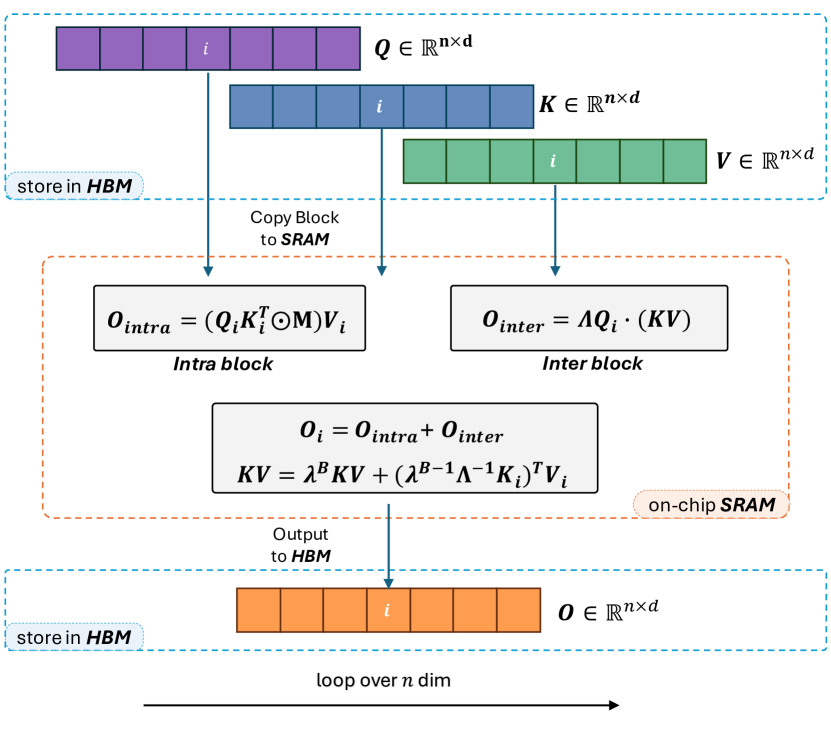
- 在第 i 次迭代期间,注意力矩阵先分块,然后从高带宽内存(HBM)传输到静态随机存取存储器(SRAM)
- 块内和块间操作被分离,块内使用左乘,块间使用右乘(应用线性注意力核技巧,发挥右乘的计算和内存优势)
- 中间激活值 $KV$ 在SRAM 中迭代保存和累计;而块内与块间的输出求和结果 $O_{i}$ 则回写到 HBM 中
LA2 的核心特点:(1)分块计算(2)右乘加速(3)GPU 硬件存储优化
最终实验结果:
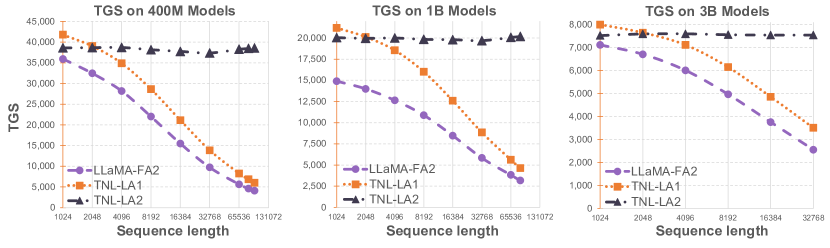
- 横轴:输入的序列长度;纵轴: 单 GPU 每秒 Token 数(TGS)
- Lightning Attention-2 在面对不同尺寸模型时,均表现出一致的训练速度
- Lightning Attention-2 在面对不同序列长度时,均表现出一致的训练速度
Lightning Attention 借鉴了 Flash Attention 分块计算和硬件加速的思想,并在此基础上进一步优化处理累积求和(cumsum)导致的性能问题,从而实现了真正的线性注意力实现(在固定内存消耗下保持不同序列长度的恒定训练速度) 注意: Lightning Attention 的项目关注度较低,稳定性和兼容性待验证,生产环境不推荐
NSA
Native Sparse Attention(本地稀疏注意力机制)
NSA 框架概述
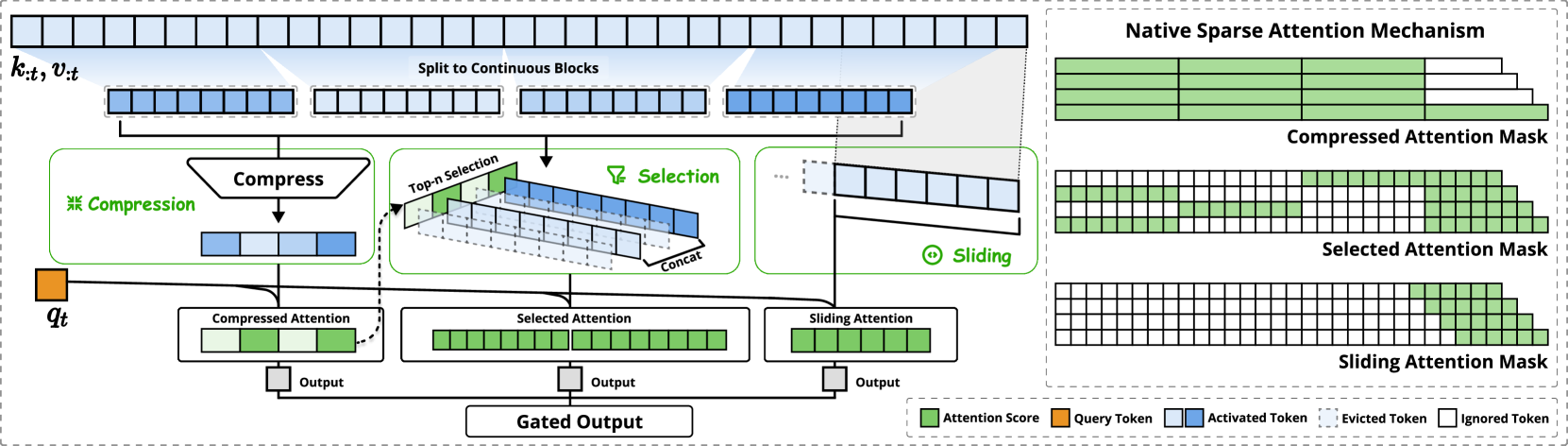
- 给定输入序列,NSA 会使用三个并行的注意力分支处理分块后的输入(1)压缩(Compression):将包含连续的键(key)和值(value)块压缩聚合为块级表示(2)选择(Selection):结合块级表示,筛选并保留包含关键信息的键(key)和值(value)向量(3)滑动(Sliding):引入滑动注意力,来单独处理局部上下文信息(其他分支都更关注全局信息)
- 右图是对三个分支下的注意力可视化,其中的白色区域表示可跳过的区域(稀疏性,加速计算)
内核设计优化:(1)分组进行数据加载(2)组内共享 KV 索引来避免冗余的 KV 传输(3)计算负载均衡
最终实验结果:
- 训练表现出稳定且平滑的收敛性,最终性能略胜普通的注意力模型
- 64k 上下文的情况下,前向传播加速 9x,反向传播加速 6x,推理加速 11.6x
MoBA
Mixture of Sparse Attention(混合稀疏注意力机制)
MoBA 框架概述:
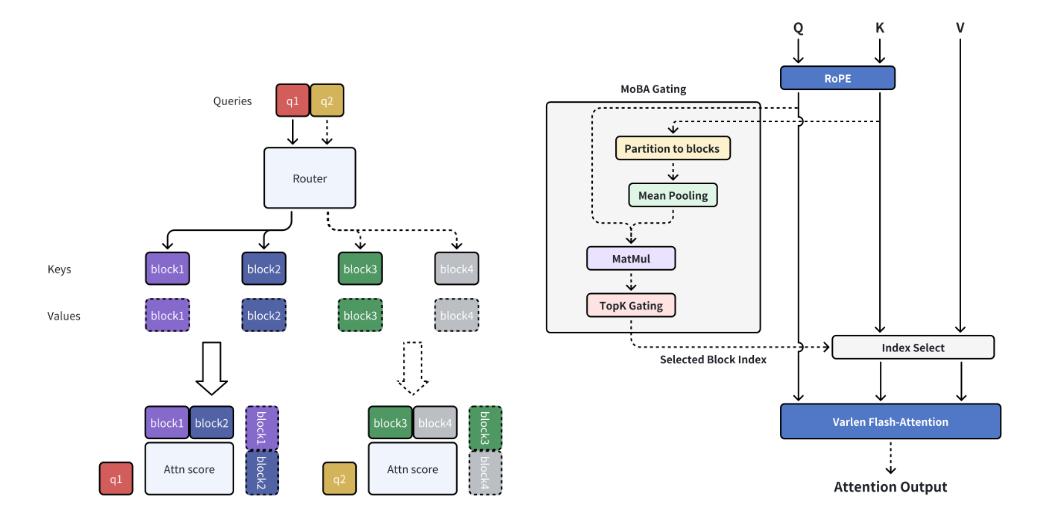
- 可训练块稀疏注意力(左):将完整上下文划分为块,其中每个查询标记学习关注最相关的 KV 块,从而实现长序列的高效处理
- 无参数门控机制(右):提出了一种新颖的无参数 top-k 门控机制,用于为每个查询标记选择最相关的块,确保模型只关注最有信息量的块
- MoBA 支持在全注意力模式和稀疏注意力模式之间灵活的无缝切换
最终实验结果:
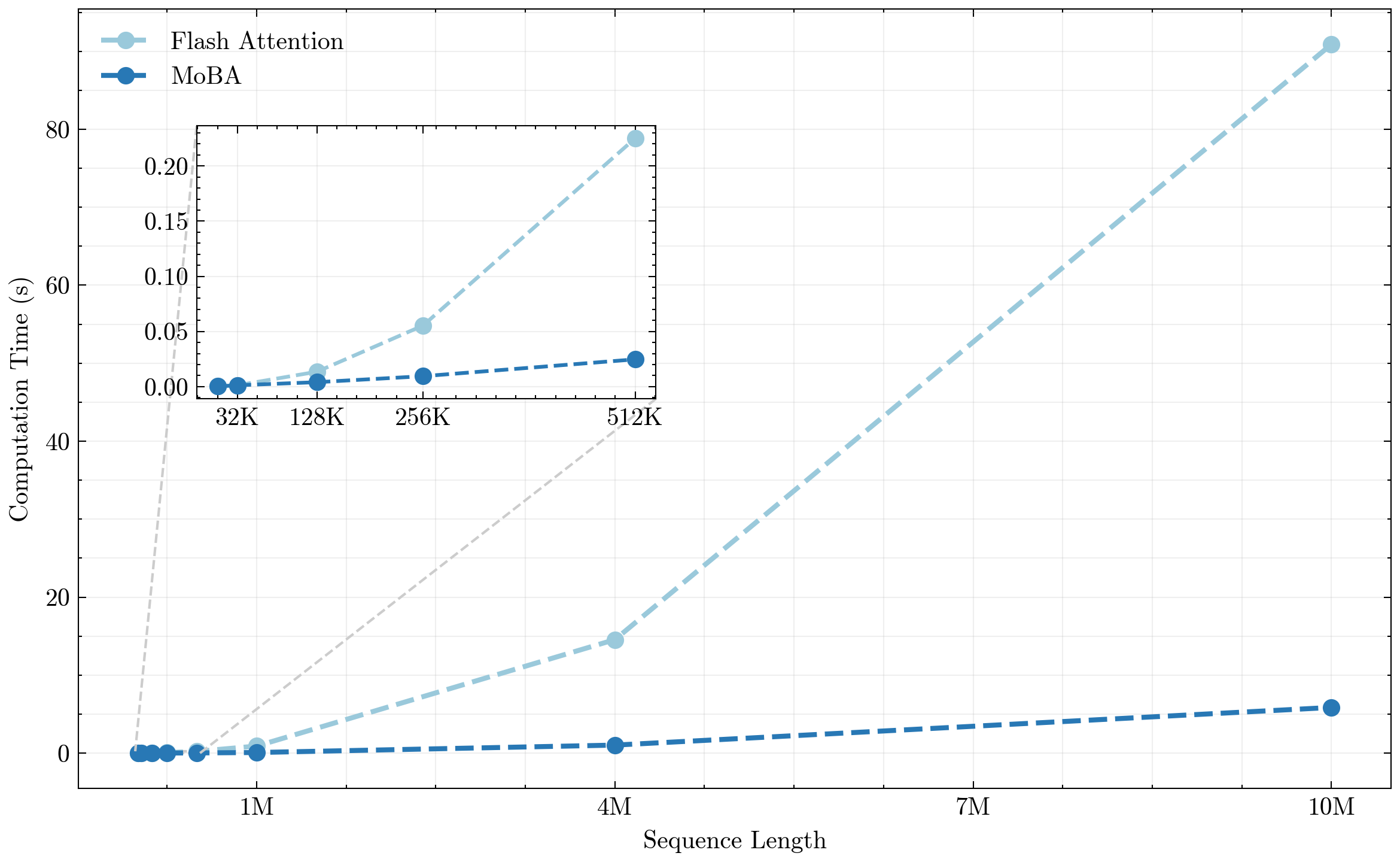
- 随着序列长度的增加,MoBA 的计算成本远低于 Flash Attention
注意力的稀疏性随着输入序列长度的增加而逐渐增强,因此基于注意力得分筛选并保留 TopK 的过程是合理的,能够在保持性能不变的情况下大幅降低计算成本 稀疏注意力的概念也受启发于 MoE(混合专家模型),即通过设计门控机制(gate),让模型自己理解“哪些 token 之间是强相关的”,“哪些信息是更值得模型关注的” 以上言论摘录总结自曹士杰老师的知乎问答
DeltaNet
在 9 月和 10 月底,阿里巴巴和月之暗面先后开源 Qwen3-Next 和 Kimi Linear 模型,其中的注意力机制都使用了线性注意力 DeltaNet 和 full attention(传统的全注意力)混合的方式