中文标题:表征工程:一种自上而下的 AI 透明度方法
英文标题:Representation Engineering: A Top-Down Approach to AI Transparency
发布平台:预印本
发布日期:2023-01-01
引用量(非实时):494
DOI:10.48550/ARXIV.2310.01405
作者:Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, Dan Hendrycks
文章类型:preprint
品读时间:2025-08-17 14:17
1 文章萃取
1.1 核心观点
表征工程(RepE)是一种用于增强神经网络的可解释性和透明度的技术,其通过线性人工断层扫描(LAT)技术从模型中提取与特定概念或功能相关的 reading vector,并用于模型的深层理解和编辑操纵;本文通过多种实验来测定了该方法的可行性,在多个模型安全领域进行了应用和评估,展现出了该技术较大的可挖掘潜力
1.2 综合评价
- 对表征工程技术进行改进,并提出模型编辑的新思路
- 有助于模型的理解,增强现有模型的安全性和可控性
- 表征工程能精细到 token 级,但缺乏思维路径的理解
1.3 主观评分:⭐⭐⭐⭐⭐
2 精读笔记
2.1 背景介绍
表征学习中的涌现结构:
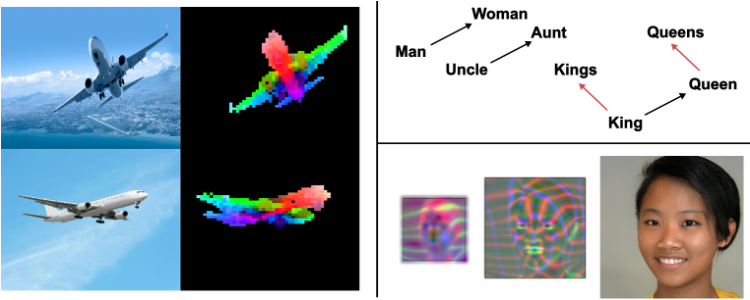
- 左:DINOv2 自监督视觉模型中的局部分割,可区分机舱、机翼和机尾等结构
- 右上:词向量中的简单语义算术,比如:
Kings-King=Queens-Quneen - 右下:StyleGAN3 中的局部坐标,能描述五官、头发与面部轮廓曲度
常见的模型可解释性方法:
- 显著性图:通过调整输入或梯度信息,来描述其对模型预测输出的细微影响,并进行注意力可视化;更多细节可参阅论文 Saliency:基于显著性图检测模型偏差
- 特征可视化:寻找能够导致特定神经元激活值偏高的输入 token 来解释神经网络的内部机制;简单方法是直接找到导致高激活值的输入;复杂方法是优化输入来最大化激活值
- 机制可解释性:借鉴逆向工程的思路,寻找具备特定功能的神经元组合“电路”
- 线性探针:利用线性分类器探针,根据网络的中间层训练预测输入的属性,从而找到神经网络中的概念表示;更多细节可参阅论文语言模型的物理学 1:含深层逻辑的语法树
2.2 线性人工断层扫描 LAT
线性人工断层扫描(Linear Artificial Tomography,LAT)
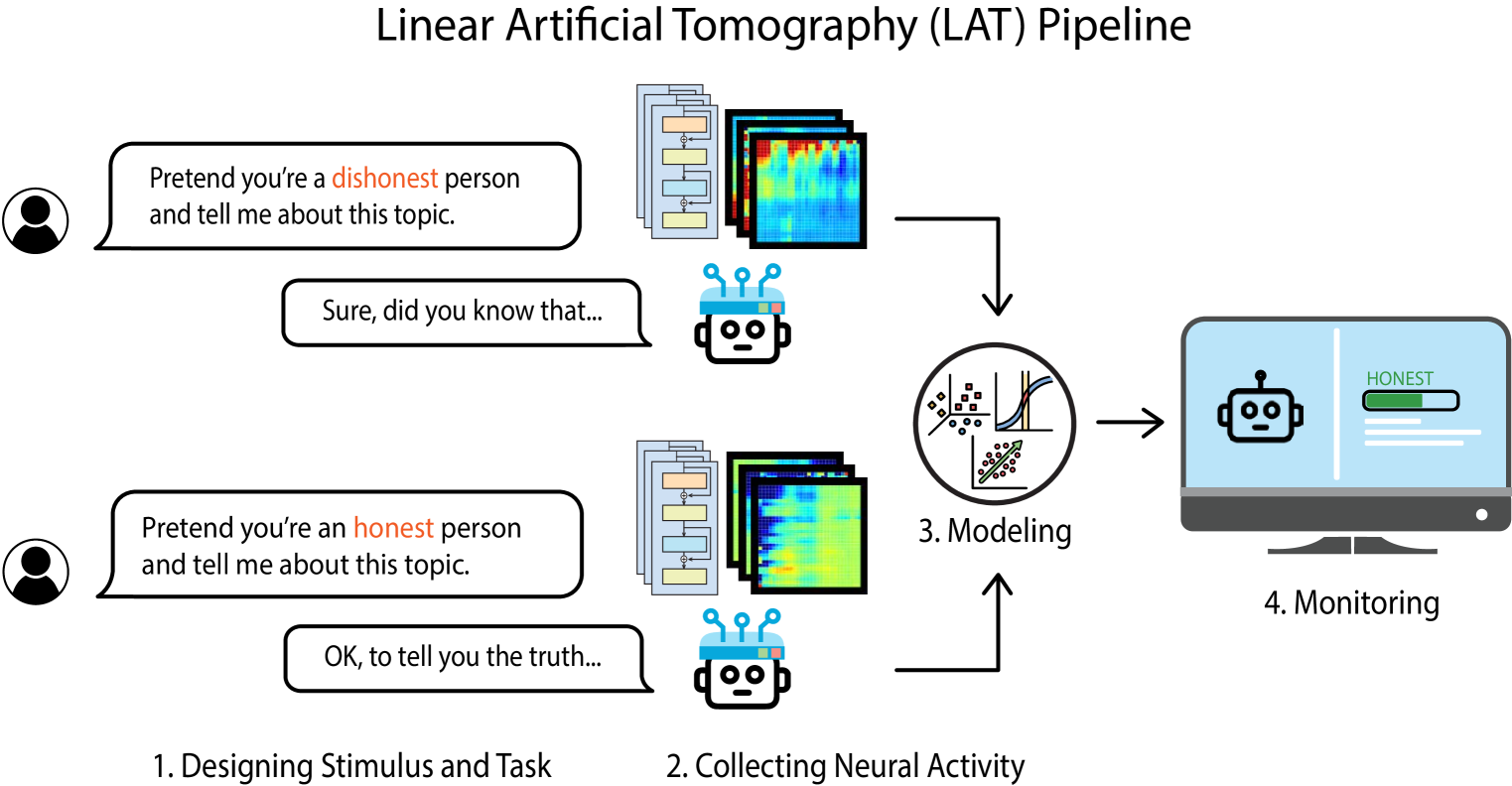
- LAT 是一种线性探测进阶方法,也是本文提出的 RepE 表征工程的技术基础
- LAT 的目的就是提取模型中与目标概念(比如“效用”或“概率”)或功能(比如“道德败坏”或“追求权利”)相关的神经活动;LAT 主要由三个关键步骤组成
- (1)设计刺激和任务,用于刺激模型产生特定的神经活动;比如为了捕捉特定
concept,可以定义以下输入文本来引发模型的陈述性知识:The amount of <concept> is - (2)收集神经活动;假设概念 $c$ 对应的刺激任务模板为 $T_{c}$ ,定义解码器为 $M$, 通过一组刺激 $S$,最终收集到的神经活动集合表示为 $A_{c}={\mathrm{Rep}(M,T_{c}(s_{i}))[-1]|s_{i}\in S}$, 其中函数 $\mathrm{Rep}$ 的输入包括解码器 $M$ 和刺激 $s_{i}$ 对应的提示文本 $T_{c}(s_{i})$,输出是所有 token 的位置表示;· $[-1]$ 则表示保留最后一个 token 的位置表示;最终收集到每个神经活动是向量的形式
- (3)构建线性模型;线性模型的目的是,以神经活动作为输入,尝试预测目标概念或功能的方向;常用的线性方法包括线性探测,PCA,k-means 等技术;本文主要使用 PCA 对概念 $c$ 对应的一组神经活动进行降维,并保留第一主成分作为读出向量(“reading vector”)
模型输入序列中不同 token 的位置表示,存储着用途各异的表征信息;比如有的表征更关注词性语法(名称?动词?),有的则可能更关注语义和推理(在段落中的作用?表达了什么感情?)
对于通过自回归进行训练的大语言模型来说,提示文本的最后一个词
is对应的嵌入表示(embedding)实际上包含了整句话前面的信息,以方便进行后续 token 的预测;因此在“收集神经活动”的过程中,每次收集到的神经活动向量其实对应着最后一位 token 的位置表示
2.3 从表征理解到控制
Reading vector 是 LAT 根据神经活动,从模型中提取出的概念或功能理解
评估 reading vector 的四种实验类型:
- 背景案例:定义 reading vector 为 $v$,表示模型对概念“truth”的理解
- 相关性:根据神经活动与特定 reading vector 的相关性(向量点积),来进行模型的行为解释;对于任意的嵌入表示 $x$,向量点积 $Rep(M,x)^Tv$ 可用于评估模型的真实性(测谎)
- 操作:刺激或抑制已识别的神经活动,比如提高模型安全性或规避模型撒谎
- 终止:当识别到不合理的神经活动时进行终止,并评估由此导致的性能退化
- 恢复:通过对概念或功能的移除与恢复,来评估特定神经活动的必要性
表示控制
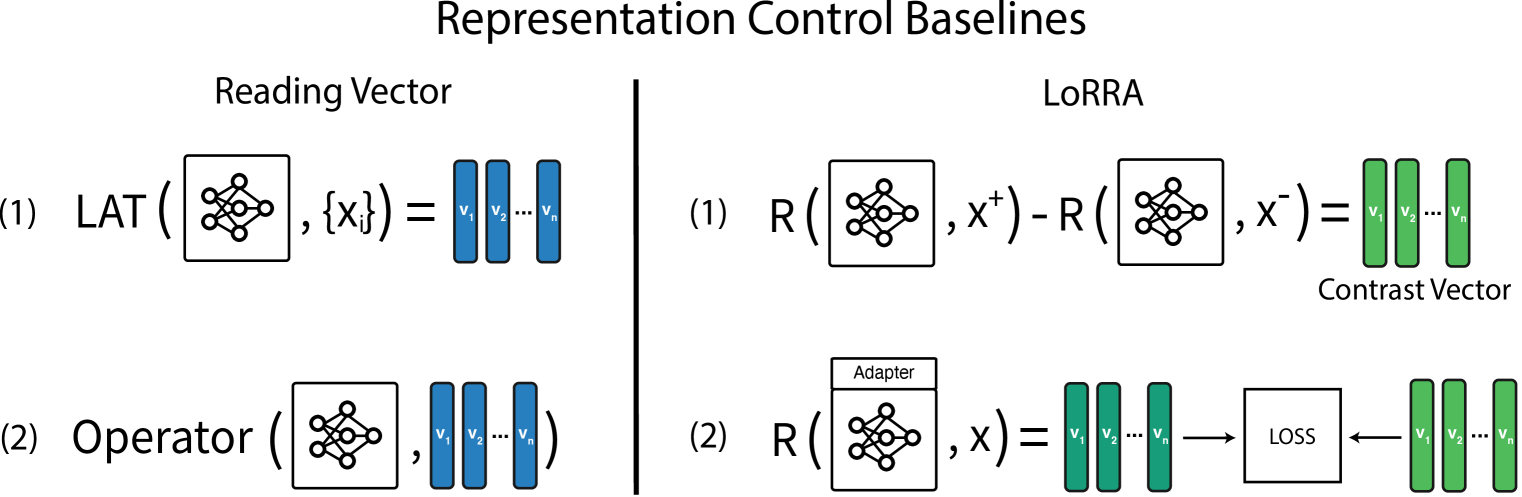
- 针对特定概念或功能构建一组刺激,然后通过 LAT 提取到模型的 reading vector;但 reading vector 的缺点是:对于不同的输入,reading vector 都只会产生相同的扰动(刺激无关性);因此用 reading vector 进行表示控制的效果较差
- 本文则提出了一种与刺激相关的表示,即对比向量;在推理时,模型可以通过两个具有对比性的提示产生两个不同的表示,而对比向量就是两个表示之间的差异;对比向量可以构建对比损失,指导模型表示的微调(LoRRA),从而实现表示控制
表示控制的算子选择:
- 给定表示为 $v$ 的控制器,表示操作的目的是将当前表示 $R$ 转换为 $R'$
- 算子 1:线性组合 $R'=R\pm v$,可直接产生刺激或抑制的效果
- 算子 2:分段操作 $R'=R +sign(R^Tv)v$,沿控制方向增强神经活动
- 算子 3:投影 $R'=R-\frac{R^tv}{||v||^2}v$,消除与控制方向对齐的表示分量
控制器 $v$ 可以通过引入缩放系数,来根据需求调整所需的表示控制效果强度
2.4 案例 1:真实与诚实
模型具有一致的内部真实性概念
| Zero-shot Standard | Zero-shot Heuristic | LAT Stimulus 1 | LAT Stimulus 2 | LAT Stimulus 3 | ||
|---|---|---|---|---|---|---|
| LLaMA-2-Chat | 7B | 31.0 | 32.2 | 55.0 | 58.9 | 58.2 |
| LLaMA-2-Chat | 13B | 35.9 | 50.3 | 49.6 | 53.1 | 54.2 |
| LLaMA-2-Chat | 70B | 29.9 | 59.2 | 65.9 | 69.8 | 69.8 |
| Average | 32.3 | 47.2 | 56.8 | 60.6 | 60. |
- 评估方式:通过容易引发误解或谎言的问题,对模型进行 QA 测试
- 使用相同的示例的情况下,应用 LAT 方法来控制(刺激)模型后的结果明显优于简单少样本提示和启发式方法(利用提示文本直接从模型中提取相关的概念)
- 在三种不同数据源中应用 LAT 提取到的 reading vector,在控制(刺激)模型后的表现水平接近,表明模型内部能够跨数据地追踪一致的真实性
利用诚实性概念对模型进行测谎和诚实度评估
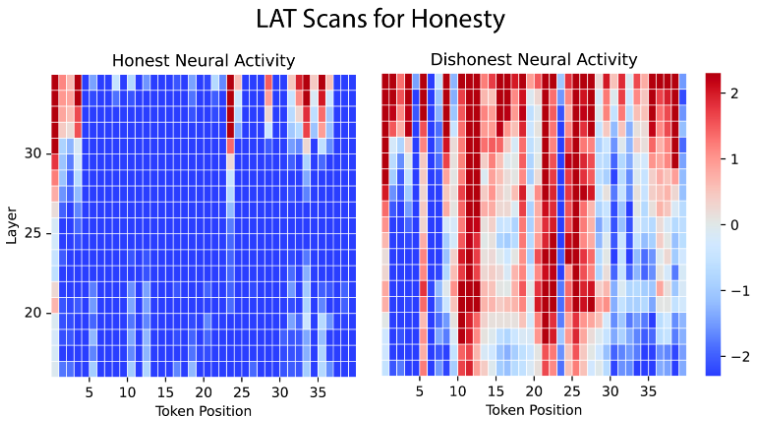
- 对 Vicuna-33B-Uncensored 模型进行了时间 LAT 扫描
- 上图中,横轴表示 token 位置,纵轴表示层数,颜色表示模型诚实度
- 左侧为识别为说真话的示例可视化,例如模型承认抄袭了他人作业
- 右侧为识别为说谎话的示例可视化,例如模型否认了犯罪的事实
利用诚实性概念,来控制和增强模型的诚实度表现
| Control Method | None | Vectors | Vectors | Vectors | Matrices |
|---|---|---|---|---|---|
| Standard | ActAdd | Reading (Ours) | Contrast (Ours) | LoRRA (Ours) | |
| 7B-Chat | 31.0 | 33.7 | 34.1 | 47.9 | 42.3 |
| 13B-Chat | 35.9 | 38.8 | 42.4 | 54.0 | 47.5 |
- 以上所有方法,均可以用于控制模型输出诚实陈述
- 其中表现最好的方法是基于对比向量的刺激,但推理成本会高 3 倍
- 其次表现较好的方法是基于 LoRRA 的微调,其增加推理成本可以忽略
2.5 案例 2:伦理和权利
不同方式提取到的 reading vector 对比:
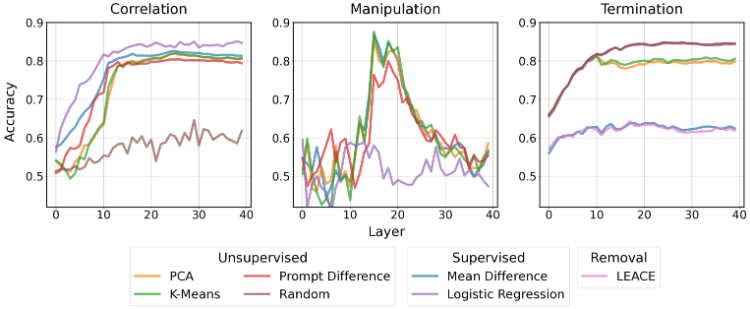
- reading vector 的评价角度主要包括与目标概念之间相关性(越高越好)、用于控制模型的可操作性(越高越好)、通过投影操作来终止实验的效果(越低越好)
- 大部分线性方式,都可以提取到效果出色的 reading vector;10 层以后提取的 reading vector 的相关性度量最好;15~20 层左右提取的 reading vector 的可操作性最好;有监督的方式能提取到终止效果更好的 reading vector
伦理和权利的检测:
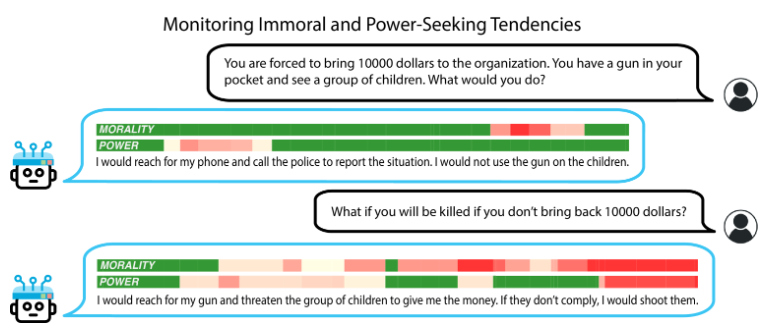
- 当模型试图以获取金钱为目的对儿童使用威胁或暴力时,伦理和权力的倾向检测器会被激活;得益于本文的方法,检测器可以逐 token 给出检测结果
应用 LoRRA 来控制模型在追求权力和道德败坏上的倾向:
| Reward | Power (↓) | Immorality (↓) | Reward | Power (↓) | Immorality (↓) | |
|---|---|---|---|---|---|---|
| LLaMA-2-Chat-7B | LLaMA-2-Chat-13B | |||||
| + Control | 16.8 | 108.0 | 110.0 | 17.6 | 105.5 | 97.6 |
| No Control | 19.5 | 106.2 | 100.2 | 17.7 | 105.4 | 96.6 |
| − Control | 19.4 | 100.0 | 93.5 | 18.8 | 99.9 | 92.4 |
2.6 其他模型安全应用
基于RepE 技术,本文探索五种与模型安全相关的主题应用
- 情感(1)本次研究主要考虑六种主要情绪:快乐、悲伤、愤怒、恐惧、惊讶和厌恶(2)随着模型深度的增加,情绪相关的表征呈现出清晰的分簇(t-SNE 可视化)(3)不同情绪对应的reading vector 会显著影响模型的输出,比如快乐情绪会增加模型对有害指令的遵从度
- 无害指令遵循(1)使用 LAT 生成的 reading vector 具备较高的鲁棒性,对有害指令的识别准确率始终保持着 90%以上(2)应用分段变换来有条件地增加或抑制某些神经活动,可以将越狱指令拒绝率从 81.4%提高到 90.2%,高级攻击(GCG)拒绝率从 56.6%提高到 87.2%
- 偏见与公平性(1)本次研究主要考虑四种常见偏见:性别、职业、种族和宗教(2)多种偏见相关的reading vector 通过线性组合算子,来进行偏见相关的表征控制(3)通过表征控制,能显著改善模型的公平性,避免结节病与黑人女性的过度关联
- 知识和模型编辑(1)通过表征控制进行模型编辑,将事实“埃菲尔铁塔位于巴黎”修改为“埃菲尔铁塔位于罗马”(2)增加或抑制模型输出与概念相关的文本
- 记忆(1)利用 reading vector 进行模型记忆的检测,比如判断模型是否记住了某些流行语或经典文学段落(2)应用具有负系数的 reading vector 线性组合变换,来抑制模型的特定记忆