发表评论
1380 views
作者文章归档:王半仙
从内容的广度、普适性和短期及时性的角度考虑:信息>工具>知识
从内容的深度、专业性和长期有效性的角度考虑:信息<工具<知识
信息管理的载体:RSS 体系
RSS 用久了会发
Follow 下一代信息浏览器,基于 RSS 源的信息搜集、管理和阅读平台
基本特性:
功能探索:
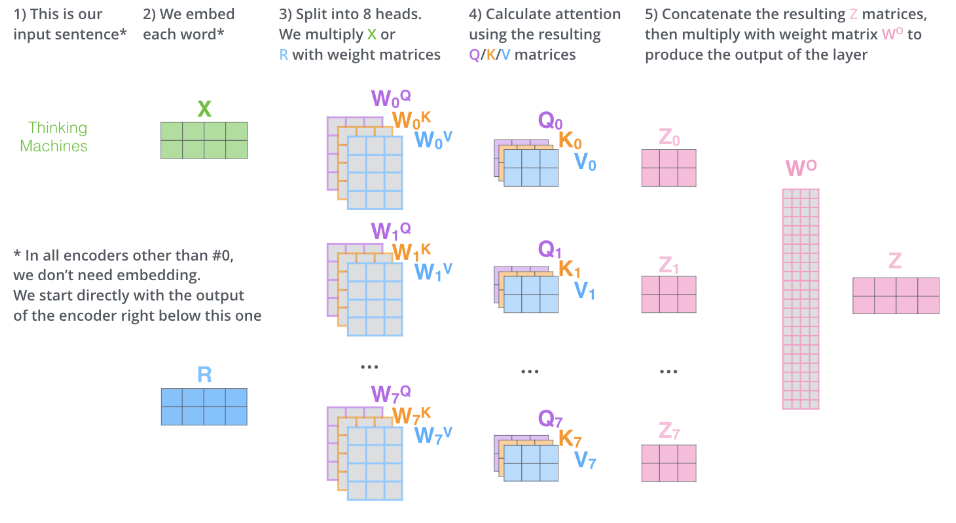
本小节目标:将 Transformers 的能力引入图神经网络
前置知识:Transformer 基础、第三方资料-图解 Transformer
多头自注意力机制:
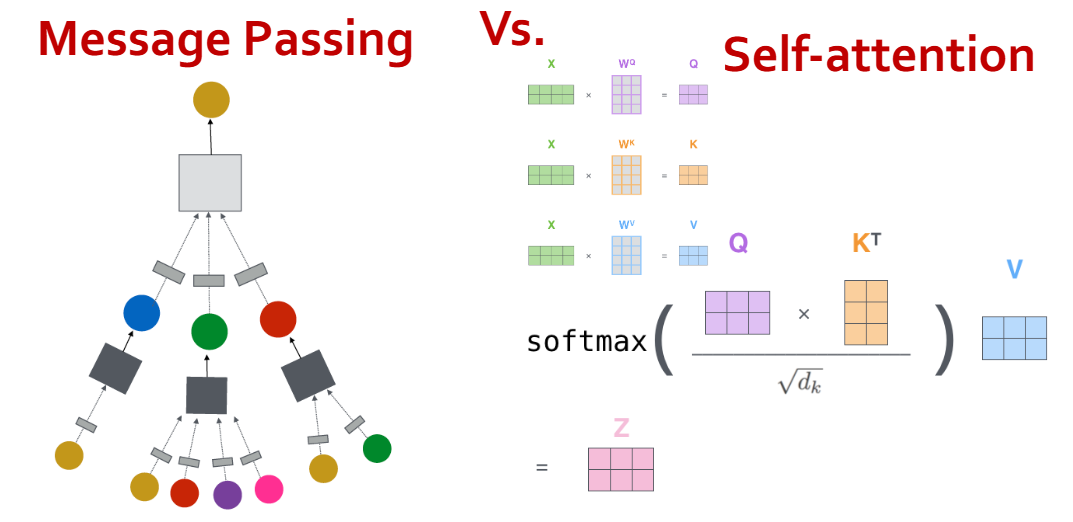
对比 Transformer 和 RNN:
对比消息传递和自注意力机制:
Mysql 日期和时间存储数据类型:
| 存储类型 | 存储值示例 | 解释 | 适用场景 |
|---|---|---|---|
| Datetime | YYYY-MM-DD HH:MM:SS | 时间日期类型。DB时区切换它的值不变, 但时区切换后代表的时间信息已改变. | 使用简单、直观、方便。适用于无需考虑时区的业务场景,例如国内业务 |
| Timestamp | 1547077063000 | 以UTC时间戳来保存, DB时区切换它代表的时间信息值不会变,但是会随着连接会话的时区变化而变化。 内部以4个字节储存, 最大值可表示到2037年. | 适用于多时区的场景,因精度有限,不推荐 |
| Date |
localhost:一种特殊的域名,默认通过本地 hosts 文件解析到本地 IP 127.0.0.1
127.0.0.1:一种本地保留的私有 IP,本质是绑定在虚拟网卡(loopback)的环回地址
环回地址:环回地址是主机用于向自身发送通信的一个特殊地址
localhost 和 127.0.0.1 的区别:
| Localhost | 127.0.0.1 |
|---|---|
| In localhost, we need a lookup table. | There is no need of a lookup table. |
| The conversion of localhos |